The problem with using a parse tree or an AST is that the parser has to throw away all conditional compilation blocks that are inactive, because you can’t really represent conditionals in the AST (at least when conditional compilation can occur basically everywhere like is the case in Haxe). So if you had a code formatter based on an AST in Haxe, it would only be able to format sections that are active (and you’d have to supply it with a list of active defines). haxe-formatter is able to format everything, because it does still have all the information present in the source file. In fact, rather than formatting specific things, it just reprints the whole file according to the formatting rules. I believe clang-format uses a similar approach and is also based on tokens rather than an AST.
Another example where we use tokentree are the document symbols and folding ranges in haxe-language-server. Again, same reasoning: if we used an AST here, we would miss all the inactive sections. Plus, these work fine even if the file isn’t a syntactically valid Haxe file yet, which happens often in IDEs while the user is typing (parsers can also deal with this with “resuming” etc, but here we more or less just get that for free).
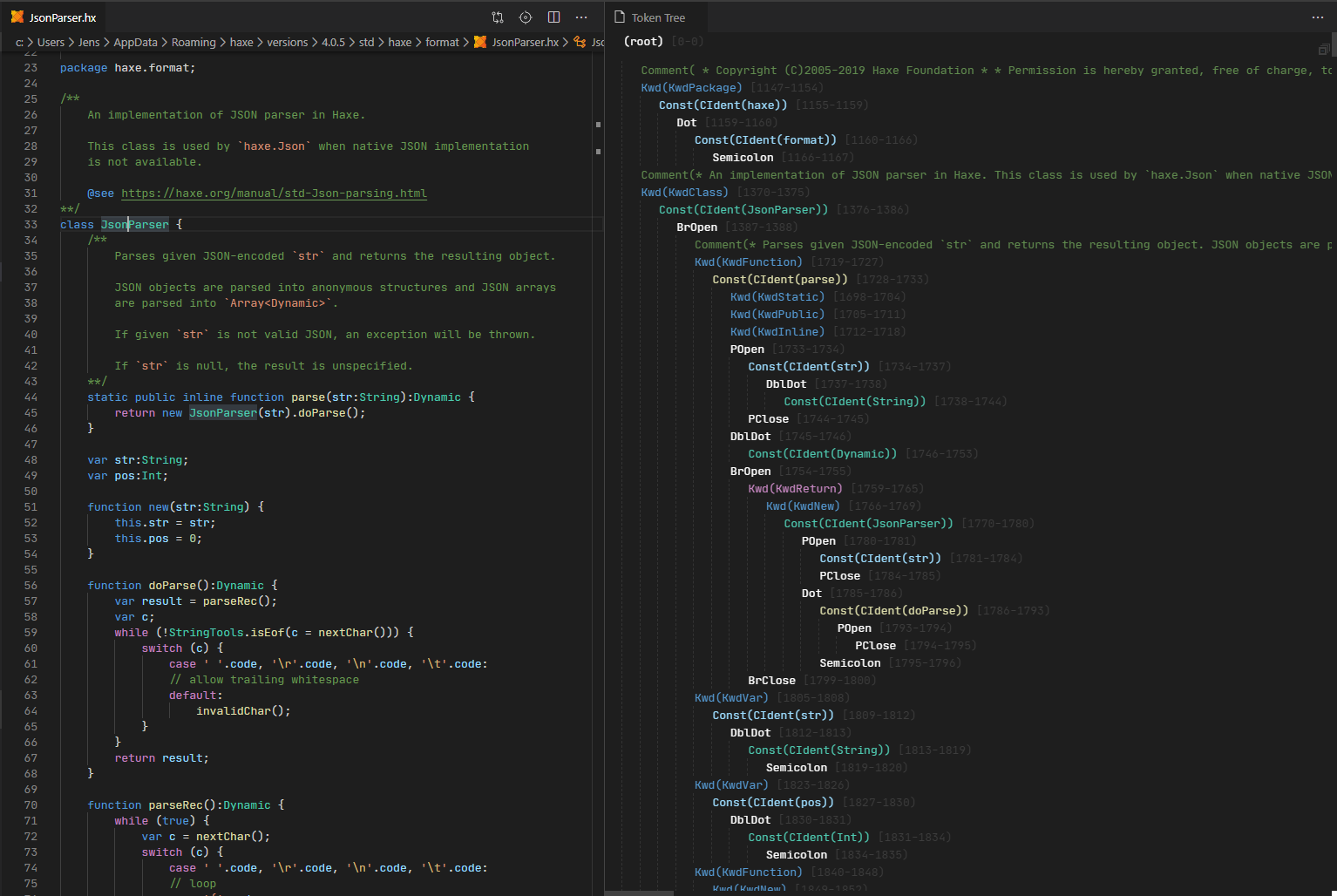
Since this may be a bit abstract, here’s a visualization of the token tree (using vshaxe-debug-tools). Tokens don’t always appear in the tree in the same order in which they occur in the source file, but are instead strucutred in a way that’s convenient to work with. For instance, the static / public / inline modifiers are children of the parse identifier token.
I guess you could say that tokentree is somewhere between raw tokens / lexer output and a parse tree. It’s based on lexer output, but not quite as high-level as a parse tree.
An abstract syntax tree is just that, abstract. It’s common to discard information that aren’t required for further processing, such as whitespaces and comments. Any syntax-formatting tool needs an accurate representation of the document, which is what token-tree provides.
For example, a parser could (we don’t) emit the same syntax node for both if (e1) e2 else e3 and e1 ? e2 : e3. To a compiler consuming that AST, it makes no difference which syntax was used to express the conditional. On the other hand, you don’t want a syntax formatter to conflate both syntaxes and transform one into the other.
Initially tokentree was an experiment to come up with a data structure that can hold a full Haxe file and provides an easy way to search for specific tokens. It went well enough that we started to build checkstyle checks with it and used it as a third engine for checks.
A little while after splitting tokentree off into its own repository, work on a Haxe formatter prototype started. Formatter version 1.0.0 was released on haxelib [edit]and with vshaxe[/edit] about 7 weeks after that.
I think it’s very safe to say that without tokentree there would be no formatter. As far as I know there have been multiple attempts by different people at writing one, but none went far enough for production code. And I think the main reason they failed or were abandoned was that prior to tokentree there was no data structure to hold a full Haxe file in memory - especially when that file also has conditional compilation sections or comments. And you will have a hard time formatting a file without being able to do it in memory, because you need a way to revert decisions about whitespace at different formatting stages and that window closes once you start writing to file.
Technically tokentree takes tokens from lexer and wraps each Token instance with a TokenTree instance, adding links to its parent, siblings and a list of childs to it. A parser-like collection of functions then tries to organise each TokenTree instance into a tree structure, setting parent, siblings and childs accordingly.
As has been said the order in which tokens appear in the tree is not necessarily identical to how they appear in source code. Tokentree tries to place tokens in a way that they create some kind of meaning in regards to its use cases (mainly checkstyle and formatter).
Since every node in a tokentree is a TokenTree instance, traversing it is very easy and can be done with a few lines of code. Furthermore having parent and sibling links allows navigation from any node to any other node.
On the other hand you are always looking at only one token, so if you need more context, if you want to know why that token is there or what it does, you need to look around and deduce its use and place from surrounding tokens. Which can be challenging or ambiguous.