New month, new update video!
")
New month, new update video!
It’s been many years since the start of the project. I wanted to give a small reflection on the mistakes made along the way, where it’s ended up and what the future may have in store.
haxe.io.Bytes, haxe.ds.Vector, Array, haxe.Rest if you ever need to create custom data types and change between any of these types, do yourself a favor and just pick Array, so much extra code and headaches were caused swapping between these types.net/http and it should have been fixed as soon as it was known.I hope the above is not too off topic, I think as a community we are inclined to chase compilers and really hard daunting problems. I hope my mistakes shared openly might nudge one or two of you, to join up with others, ambitiously, over plan and under engineer the next great Haxe project (while using it yourselves).
I went from 0 understanding of compilers when I started this project to standing here with just a little more. I’ve met unbelievably talented developers here, and it’s been such a joy, to share, build and hear all the awesome changes in this quite tight nit community.
I’d also like to thank Elliott Stoneham, who I never would’ve gotten this far without his constant unwavering support week in and week out. It’s been an honor to follow in his footsteps and I stand on his outstanding work alongside the Haxe contributors and library maintainers.
The Go standard library net/http being used to run a web server in Haxe on hashlink. (also supports SSL)

Whatever I do in the future, I want to build with others. Haxe is rare that it has such an open community with at the same time such dense talent. I’d like to leverage that, and work on something together that fundamentally makes Haxe more awesome to use.
FWIW, I would think that a Go backend (even a macro powered custom target) might be a better approach here, assuming you can find a neat way to embed Go semantics into Haxe.
There are two advantages to this:
go/parser, go/token and go/types and what not to deal with Go). Takes in Go code, spits out Haxe - could initially just start with generating externs, later generate code.Dunno. Maybe I’m just being naive here, but it sounds less ambitious than having to reimplement half the Go compiler in Haxe.
In any case, really nice project. You’ve accomplished much ![]()
@back2dos Thanks for the kind words! Your points are well reasoned, I think it is indeed paradoxically less ambitious. Though go2hx already use’s Go’s frontend, building a Go backend first to bootstrap go2hx later on, has a number of benefits you’ve rightly pointed out. In addition here are some that come to mind for both unambitious projects (would love to hear any others ideas that come to mind!):
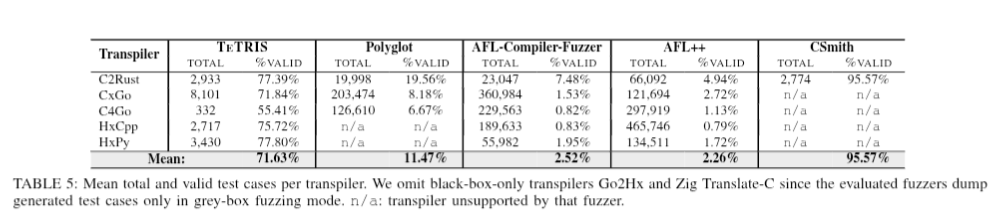
I also decided to write a review today on a research paper done by Yeaseen Arafat from the university of Utah. The work evaluated go2hx (and other compilers) with a new state of the art general purpose transpiler fuzzer, TeTRIS!
PDF of paper
Reported go2hx bugs
I’m very happy that a project we’ve passionately worked on for so long, is included in cutting edge research and directly benefiting from it. I have a lot of respect for Yaseen and sincerely believe a feedback loop of compiler dev teams using + giving feedback / contributing to improve the next generation fuzzers will advance the field tremendously.
I was expecting above 90% validity for TeTRIS, would’ve been nice to get the details on why the Haxe generation is around ~75% and how it could be improved. Haxe is probably one of the best languages to run the fuzzer on, because it can be used to compare all of it’s backends which could likely use a lot of help finding corner case bugs and defining the undefined behavior regions across targets.
I mention this because, if I’m not mistaken, CSmith did the same thing with clang and gcc to perform differential testing. In my view this is a very under tapped field of research.
I’m sold on the idea conceptually, that TeTRIS should be one of the key tools used when designing source to source compilers. Given the alternatives and many of the exclusions of other fuzzers that were made because of language/feature limitations, it’s clear that this is a novel approach that has the potential to not just advance research but also bring about more mature transpilers in a shorter time frame. I could also see it or a future iteration, being the premier tool to use when developing a Haxe backend or transpiler into Haxe. I hope that the momentum continues and that TeTRIS blossoms into a useful and community driven open source project.
Yeah, I didn’t want to discourage you from pursuing your prior direction, but on paper it seems a bit of a moonshot goal. The progress you’ve made goes to show that it’s actually far more feasible than I would’ve thought. But it’s clear that the size of the task puts a strain on you.
So while I haven’t fully mapped out the journey, it does seem to me that going hx2go produces a path with more intermediary results that are meaningful by themselves and makes it easier to keep the ball rolling, from stage to stage:
the value of “just” a Go backend by itself is quite self-evident and as you pointed out, it is also quite achievable (I kinda expected that, but my knowledge of Go is superficial at best):
an externs generator (based on an hx2go backend and thus being able to leverage Go compiler code) is both an important step towards a fully blown go2hx, but has value of its own:
in many ways a full go2hx will snap in like the final piece of a puzzle - in many ways it won’t, because the prior steps leave substantial problems untackled, but still I would imagine that having a working Go + Haxe → Go pipeline significanly helps in sorting those out
No doubt I am missing something, but my intuition tells me that going this way would line up a bunch of small victories all the way to the grand goal. That sure goes a long way to building and keeping momentum.
When it comes to dog fooding (which is crucial IMO), you’ll want to think in terms of use cases. Who would use this and for what? For go2hx it’s not immediately clear what the real world use case is (especially one that is so crucial that one would accept the rough edges that will take years to sand off). I would place Go’s primary strength as server development, especially due to its runtime (native binaries, fast GC, great concurrency model). So I wonder if switching out that runtime really leads to worthwhile results outside various edge cases. From a Haxe perspective, Go would make for a very intersting server target for game developers (also for web developers like myself, but there’s not so many left), that would most likely outperform all available targets for most types of servers. There’s a tangible benefit to people already sold on Haxe.
I can see the usefulness, especially in later phases of the project. But I’m not sure it’s something I would get overinvested in early. Formal correctness has been a highly sought after ideal ever since computer science began taking shape. But it is an ideal, which is rarely accomplished fully and at times adds significant cost that sacrifices other important qualities. What qualities are truly important in the real world really is determined in the real world (which is why some of the most popular software out there horrifically broken in many ways and yet too useful for people not to use). You should thefore try to build a small community around not just some tooling, but a real use case.
A possible example: make a haxe+go game server. Take a look at colyseus and similar alternatives to pick a meaningful, achievable subset of common features. Perhaps there are some neat Go libs that could help you get somewhere fast. You should also consider hxbit for serialization/sync/rpc. And see if there’s any value in providing integrations with the more popular Haxe game frameworks. I would like to think that this would be the type of project around which a handful of people could gather.
You can of course try to draw together people who approach this from a purely academic angle. But that runs the risk of getting lost in theoretical musing and an inability to prioritize things that have an impact. Also half of them might jump ship when the next paradigm shifting programming revolution comes along.
In any case, I think I’ve said more than enough, especially because this subject doesn’t concern me all that much (outside of personal curiosity). But you’ve put in immense amounts of effort and built much expertise on the subject of bringing Go and Haxe together. It would be really lovely to see this culminate in tooling that becomes even just a few people’s weapon of choice to ship something to production. I really wish for you to find just the right angle to pull it off ![]()
Firstly I value the honest insight, you in particular bring to the table, and I appreciate you didn’t want to discourage me, but to me, you’re presenting quite a fair course correction to get back to the goal (Allow Haxe to utilize Go’s power and libraries), rather then chasing a moonshot goal, as you rightfully said.
You’re also right it’s not immediately clear what the real world use case is, for go2hx. My initial thinking was that Go libraries, cross target would be more powerful from a Haxe perspective, then adding another target (where they would be locked to the Go target). Now with more experience trying to get the targets in practice, to work with go2hx’s Haxe code (one of the most difficult aspects), I think adding a mature target, with the characteristics of Go is in fact more valuable overall (and faster to achieve tangible value).
Yep that’s a great point! It’s one of the things I’m most excited about, as it removes the largest time sink for go2hx, which was re-implementing Go’s stdlibs in Haxe, now as long as the externs work the rest, as you said is guaranteed to work!
Indeed, I’m not too worried if the puzzle piece of a full go2hx doesn’t snap in. At least the automatic extern version of it should snap in relatively easy, and the code generation part can either be left indefinitely, or picked up, if a clear use case is selected that we want to take on.
I think you are right, we also have a team working on it and will likely get a lot more traction bringing in user and contributors alike from the amount of small victories that can and will be showed off! Hopefully many other Haxe devs will have the same curiosity as you, and might even be inclined to use, no less contribute.
We are thinking the same use cases you lined out for the Go target. In addition running hx2go on the hx2go backend (allowing us to utilize the Go printer + performance + concurrency), and go2hx also to run on the hx2go backend (access to the Go frontend from Haxe).
You’re not wrong, the only upside from a Haxe perspective is allowing Go’s library ecosystem to be used across theoretically all Haxe targets. The upside also rests on how good the current Haxe targets are relative to a potential new target. In my mind the needle has drifted far to the new target potential, because of the many inconsistent behaviors, almost all of the Haxe’s targets exhibit (+ long iteration times to fix said issues)
I agree, what is important is determined, in the real world (chasing after edge cases that never show up in real code is a waste of time), though I would wager a useful compiler has never been described as horrifically broken. Compilers by there nature are supposed to be highly correct, the real world necessitates library code written in all sorts of interesting ways, and users expect a non toy compiler to string it all together and handle it, in a correct manner.
That is a great idea, I would think it would possible as well to build such a community on a project like that. I am also quite interested in the game server angle, and a while back, I picked out a game server I want to use with Haxe, that I intend satisfyingly complete with hx2go:
Also to that point one of our team members MKI has already wrote Raylib externs for hx2go, and I don’t see him stopping to find more real world cases to dive into. He’s had a really positive effect on the team, dragging us more to the practical and showing us how fast we really can build tangible real world projects, and not just fix bugs. (discord embedded mp4 hopefully it loads ![]() )
)
I don’t disagree, the research angle at least in my view is useful in so far that it helps out, with squashing real world bugs and potentially iterating faster to reach specification compliance. I tried to choose my words carefully by describing that I’m sold conceptually, practically is a much different thing.
In particular if it was possible that I could spin up a program that could generate 10k ways to use a defined basic sub specification of Haxe language features. Where the resulting failing code is plausible to be found in the real world, and unlike the real world is already minimized (saving me a ton of time). That would be wonderful, and I would let it spin every day! That’s likely not the reality, but I’ve seen most of the bugs Yaseen has brought to the go2hx project have been applicable to the real world, and I’d like the tool I described above to exist, so maybe it’s not so far off? (Maybe I’m being naive?)
Untrue! Personal curiosity especially of your caliber and meshed with your experience, is more then welcome! At the end of the day we are all here to discuss and read about interesting Haxe problems and projects. Also for someone that professes ignorance on the subject/Go, it’s rather amusing to read you detail correctly exactly how to bring about both projects in the most ideal manner. It almost seems like you want to join in on the fun!
Thank you for adjusting the angle to give us better chances to do that! I would consider a few people shipping things to production with hx2go as a success for sure.
I already find go2hx in a way to be a success as well.
Overall the culmination of required things to give the project a long useful life is coming together, and maybe we’ll even hit some fun goals, like the first written in Haxe target, to pass all of the Haxe compiler tests?
I’ve never shipped Go code to production, which essentially means I have no idea what I’m talking about. These are pure speculations enabled by the fact that I can run over gaping chasms like a cartoon character who forgets to look down, precisely because of all the unknown unknowns born of my lack of experience in this landscape. Does my plan sound plausible? I hope so. Is it feasible? I haven’t the slightest clue! I hope there’s something useful in there, but in the end, only code can tell.
I will admit I’ve often toyed with the idea, when I was still really into that kind of thing (back when Elliott showed of Tardis at the WWX), but I’ve never taken any practical steps (except work through various Go tutorials). What stands is that the Go runtime is particularly interesting in two aspects:
Because of that, I’ve pondered this quite a bit, but again, never moved beyond theory. For my use cases in the end nodejs is simply fast enough and macros largely give me the freedom I need to make the compiler jump through the hoops I want it to, without having to mess with its internals (and also I’ve learned to be productive in far simpler languages than vanilla Haxe, so it’s not even clear to me that all this flexibility and customization is so crucial - much as I enjoy it).
All that said: this is truly an exciting project. Just the mere hope of moving away from the dull pain of dealing with node/npm in production is wonderful. But what is more: there’s no upper bound to how far you can take it. Let’s go fully crazy, ignoring all notions of effort: suppose there’s a working Go backend and Haxe is bootstrapped on top of that, it’s conceivable to have a binary that has both the Go compiler and the Haxe compiler inside - or probably two, with one compiler acting as “master” in each case - in a way that data can actually flow between them. Those dual compilers could be both go2hx and hx2go respectively. Essentially you would aim to transform some IR of Go (from my understanding there’s many and I wouldn’t know which one to pick) into Haxe AST / tAST or the other way round, without even passing through source. Only one problem: we just went from moonshot to marsshot ![]()
In any case, I’m really happy to see the progress you made with hx2go in such a short time (that Raylib vid says more than a 1000 commits). Sadly, from my side, I have stretched myself way too thin and have some 400+ open issues on GitHub in bad need of my attention. So as much as I enjoy to share in the excitement, all I can really contribute here are random ramblings, cheerleading and armchair quarterbacking. To that effect: Go! Go! Go! (pun intended).
© 2018-2020 Haxe Foundation - Powered by Discourse